Data denormalization
The data in the source database is often normalized, meaning that column values are scalar and entity relationships are expressed as mappings of primary keys to foreign keys between different tables. Normalized data models are useful when you’re inserting, updating, and deleting data at the cost of slower reads. Redis as a cache, on the other hand, is focused on speeding up read queries. To that end, RDI provides denormalization of data.
Nest strategy
Nest is the only currently supported denormalization strategy.
This strategy denormalizes many-to-one relationships in the source database to JSON documents, where the parent entity is the root of the document and the children entities are nested inside a JSON map attribute.
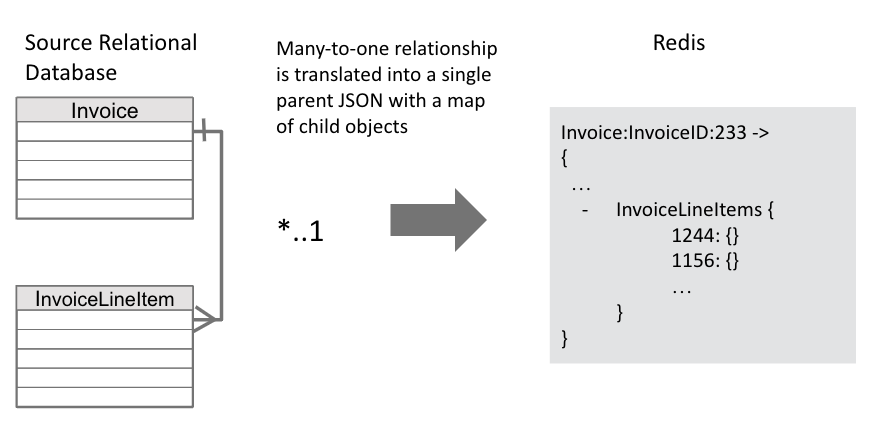
Denormalization is performed by using a nest block in the children entities’ RDI job, as shown in this example:
source:
server_name: chinook
schema: public
table: InvoiceLine
output:
- uses: redis.write
with:
nest: # 'key' parameter is not allowed with `nest`
parent:
# server_name: chinook
# schema: public
table: Invoice
nesting_key: InvoiceLineId # cannot be composite
parent_key: InvoiceId # cannot be composite
child_key: ParentInvoiceId # optional if the same as the parent_key
path: $.InvoiceLineItems # path must start from document root ($)
structure: map # optional, "map" is the only supported option
The job has a with section under output that includes the nest block.
The job has to include these attributes in the nest block:
parent: Specifies the RDI data stream for the parent entities. Typically, the parent table name is sufficient, unless you nest children under a parent that comes from a different source database. In that case, you have to specifyserver_nameandschema.nesting-key: The field of the child entity that stores the unique ID (primary key) of the child entity.parent-key: The field in the parent entity that stores the unique ID (foreign key) of the parent entity.child_key: The field in the child entity that stores the unique ID (foreign key) of the parent entity. It is optional and only required when the name of the child’s foreign key field differs from the parent’s.path: The JSON path for the JSON map of children entities. This has to start with$which is the notation for the document root.structure: The optional type of JSON structure used for nesting the children entities. Currently, only JSON map is supported so the value must bemap, if provided.
Notes:
When
nestis specified in the job, RDI automatically overridesdata_type: jsonandon_update: mergefor that output block regardless of the actual values specified in the job or system-wide settings.Key expressions are not supported for the
nestoutput blocks. The parent key is always calculated using the following template:<nest.parent.table>:<nest.parent_key>:<nest.parent_key.value | nest.child_key.value>For example:
Invoice:InvoiceId:1If
expireis specified in thenestoutput block it will set the expiration on the parent object.Only one level of nesting is currently supported.
Only applicable to PostgreSQL: To enable nested operations for tables in PostgreSQL databases, the following changes must be made to all child tables:
ALTER TABLE <TABLE_NAME> REPLICA IDENTITY FULL;For every table that has nested data in a parent document, it is necessary to perform this task. The configuration impacts the information written to the write-ahead log (WAL) and its availability for capture. By default, PostgreSQL only records the modified fields in the log, which can cause the
parent_keyto be omitted, resulting in erroneous updates to the Redis key in the destination database. Modifying the table to capture all modifications in the log is essential to ensure proper operation of RDI. See more details in Debezium PostgreSQL Connector Documentation.