Data transformation pipeline
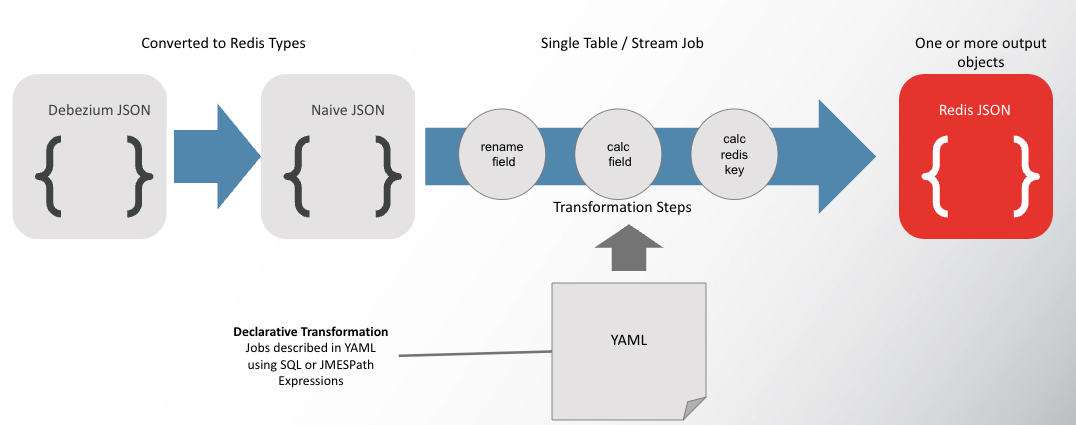
Redis Data Integration’s (RDI) data transformation capabilities allow users to transform their data beyond the default translation of source types to Redis types. The transformation involves no coding. Instead, it is described in a set of human readable YAML files, one per source table.
The ingested format and types are different from one source to another. Currently, the only supported source is Debezium. The first transformation from Debezium types to native JSON with Redis types is done automatically without any need for user instructions. Then, this JSON is passed on to the user defined transformation pipeline.
Each job describes the transformation logic to perform on data from a single source. The source is typically a database table or collection and is specified as the full name of this table/collection. The job may include filtering logic to skip data that matches a condition. Other logical steps in the job will transform the data into the desired output that will be stored in Redis as hashes or JSON.
Default job
In situations where there is a need to perform a transformation on all ingested records without creating a specific job for specific tables, the default job is used. The transformation associated with this job will be applied to all tables that lack their own explicitly defined jobs. The default job must have a table name of “*”, and only one instance of this type of job is permitted.
For example, the default job can streamline tasks such as adding a prefix or postfix to Redis keys, or adding fields to new hashes and JSONs without customizing each source table.
Currently, the default job is supported for ingest pipelines only.
Example
This example demonstrates the process of adding an app_code field with a value of foo using the add_field block to all tables that lack explicitly defined jobs. Additionally, it appends an aws prefix and a gcp postfix to every generated hash key.
default.yaml
source:
table: "*"
row_format: full
transform:
- uses: add_field
with:
fields:
- field: after.app_code
expression: "`foo`"
language: jmespath
output:
- uses: redis.write
with:
data_type: hash
key:
expression: concat(['aws', '#', table, '#', keys(key)[0], '#', values(key)[0], '#gcp'])
language: jmespath
Jobs
Each job is defined in a separate YAML file. All of these files will be uploaded to RDI using the deploy command. For more information, see deploy configuration). If you are using the scaffold command, place the job files in the jobs folder.
Job YAML structure
Fields
source:This section describes the table that the job operates on:
server_name: logical server name (optional). Corresponds to thedebezium.source.topic.prefixproperty specified in Debezium Server’sapplication.propertiesconfig filedb: database name (optional)schema: database schema (optional)table: database table namerow_format: format of the data to be transformed:data_only(default) - only payload, full - complete change record
Note: Any reference to the properties
server_name,db,schema, andtablewill be treated by default as case insensitive. This can be changed by settingcase_insensitivetofalse.
Cassandra only: In Cassandra, a
keyspaceis roughly the equivalent to aschemain other databases. RDI uses theschemaproperty declared in a job file to match thekeyspaceattribute of the incoming change record.
MongoDB only: In MongoDB, a
replica setis a cluster of shards with data and can be regarded as roughly equivalent to aschemain a relational database. A MongoDBcollectionis similar to atablein other databases. RDI uses theschemaandtableproperties declared in a job file to match thereplica setandcollectionattributes of the incoming change record, respectively.
transform:This section includes a series of blocks that define how the data will be transformed. For more information, see supported blocks and JMESPath custom functions.
output:This section defines the output targets for processed data:
- Cassandra:
uses:cassandra.write: write into a Cassandra data storewith:connection: connection namekeyspace: keyspacetable: target tablekeys: array of key columnsmapping: array of mapping columnsopcode_field: the name of the field in the payload that holds the operation (c - create, d - delete, u - update) for this record in the database
- Redis:
uses:redis.write: write to a Redis data structure. Multiple blocks of this type are allowed in the same jobwith:connection: connection name as defined inconfig.yaml(by default, the connection named ’target’ is used)data_type: target data structure when writing data to Redis (hash, json, set and stream are supported values)key: this allows you to override the key of the record by applying custom logic:expression: expression to executelanguage: expression language, JMESPath or SQL
expire: positive integer value indicating a number of seconds for the key to expire. If not set, the key will never expire
- SQL:
uses:relational.write: write into a SQL-compatible data storewith:connection: connection nameschema: schematable: target table namekeys: array of key columnsmapping: array of mapping columnsopcode_field: the name of the field in the payload that holds the operation (c - create, d - delete, u - update) for this record in the database
- Cassandra:
Notes
sourceis required.- Either
transform,key, or both should be specified.
Using key in transformations
To access the Redis key (for example in a write-behind job) you will need to take the following steps:
- Set
row_format: fullto allow access to the key that is part of the full data entry. - Use the expression
key.keyto get the Redis key as a string.
Before and after values
Update events typically report before and after sections, providing access to the data state before and after the update.
To access the “before” values explicitly, you will need to:
- Set
row_format: fullto allow access to the key that is part of the full data entry. - Use the
before.<FIELD_NAME>pattern.
Example
This example shows how to rename the fname field to first_name in the table emp using the rename_field block. It also demonstrates how to set the key of this record instead of relying on the default logic.
redislabs.dbo.emp.yaml
source:
server_name: redislabs
schema: dbo
table: emp
transform:
- uses: rename_field
with:
from_field: fname
to_field: first_name
output:
- uses: redis.write
with:
connection: target
key:
expression: concat(['emp:fname:',fname,':lname:',lname])
language: jmespath
Deploy configuration
In order to deploy your jobs to the remote RDI database, run:
redis-di deploy
Deploy configuration on Kubernetes
If the RDI CLI is deployed as a pod in a Kubernetes cluster, perform these steps to deploy your jobs:
Create a ConfigMap from the YAML files in your
jobsfolder:kubectl create configmap redis-di-jobs --from-file=jobs/Deploy your jobs:
kubectl exec -it pod/redis-di-cli -- redis-di deploy
Note: A delay occurs between creating/modifying the ConfigMap and its availability in the
redis-di-clipod. Wait around 30 seconds before running theredis-di deploycommand.
You have two options to update the ConfigMap:
For smaller changes, you can edit the ConfigMap directly with this command:
kubectl edit configmap redis-di-jobsFor bigger changes such as adding another job file, edit the files in your local
jobsfolder and then run this command:kubectl create configmap redis-di-jobs --from-file=jobs/ --dry-run=client -o yaml | kubectl apply -f -
Note: You need to run
kubectl exec -it pod/redis-di-cli -- redis-di deployafter updating the ConfigMap with either option.